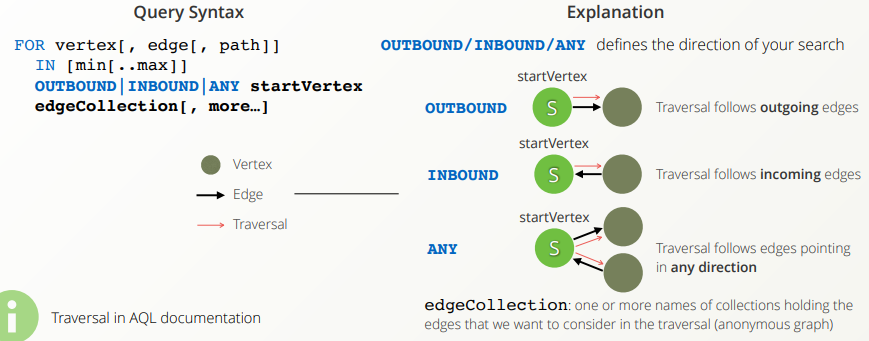
<아랑고DB> 9. 데이터 모으기 COLLECT / AGGREGATE / MIN_BY, MAX_BY
11 Dec 2021 | 아랑고DB 그래프DB1. 개념잡기
아랑고DB에서 COLLECT는 데이터를 그룹지어주는 연산자이다. SQL에서 GROUP BY와 유사한 역할을 한다고 이해하면 된다.
둘의 느낌적인 차이를 사용자 입장에서 설명해보면 이렇다.
- SQL은 데이터를 한 번에 조회해서, 기준에 따라 데이터를 그룹 연산할게요~의 느낌이라면
- AQL은
FOR루프를 돌면서 기준에 따라 데이터를 모을게요~의 느낌이다
예시를 들면, id별 최근 방문 시간을 조회한다고 가정해보자.
//SQL
//테이블 전체 조회해서 최대 시간 뽑아주세요~
SELECT
id,
MAX(visit_time) AS last_visit_time
FROM mysql.test_db.test_table
GROUP BY id//AQL
//컬렉션 돌면서 id별 최대 시간 모아주세요~
FOR data in test_collection
COLLECT
id = doc.id
AGGREGATE
last_visit_time = MAX(doc.visit_time)
RETURN {id, visit_time}AQL에서는 FOR 루프와 함께 COLLECT가 쓰이기 때문에, 데이터를 모은다라는 표현이 어울리는 것 같다.
2. COLLECT 문법 익히기
이제 실제 문법을 배워보자. 모든 자세한 설명은 아랑고 DB 공식 문서에 아주 잘 설명되어 있다.
COLLECT
variableName = expression
AGGREGATE
variableName = aggregateExpression
INTO groupsVariable COLLECT는 다양한 형태로 쓰이는데, 일단은 전체적으로 살펴보자.
COLLECT 바로 다음에 나오는 변수는 그룹의 기준이 되는 변수들을 의미한다. 좌변인 variableName은 사용자가 설정해주는 변수 이름이 되고, 우변에는 해당 값이 들어간다.
AGGREGATE는 필수 연산은 아니며, 그룹의 기준이 되는 변수들을 대상으로, 데이터에 어떠한 그룹 연산을 취할 것인지를 결정해주는 부분이다. 그룹별로 MIN, MAX, UNIQUE 등 다양한 그룹 연산을 사용할 수 있다.
INTO도 필수 연산은 아니며, 그룹별로 데이터를 묶어주는 역할을 한다. 다시 말하면, FOR 루프를 돌면서 그룹에 해당하는 모든 도큐먼트를 모아주는 역할이다.
SQL에 대응해보면 아래와 같다.
COLLECT id = doc.id:GROUP BY idAGGREGATE last_visit_time = MAX(doc.visit_time):MAX(visit_time) AS last_visit_timeINTO groups: INTO는 SQL에 대응할만한 연산자가 생각나지 않는데, 굳이 하나를 만들자면 “그룹에 해당하는 모든 레코드(행)을 묶어서 하나의 어레이로 만들어주는” 연산이라고 보면 되겠다.
3. AQL 예제를 통한 사용법 익히기
여러가지 사례를 통해 문법에 익숙해져보자. 지난 글의 공항 데이터를 사용할 예정이며, 기억이 나지 않으면 요기를 다시 보자.
횡단에서 했던 것처럼, COLLECT도 뽑을 데이터가 정해졌을 때 미리 머리속에 그려보면 좋다. 아래 세 가지를 미리 생각해보고, 코드를 짜보도록 하자.
1) 그룹의 기준을 정하고 2) 뽑을 데이터를 정하고, 3) 데이터 각각이 어떤 기준으로 뽑혀야 하는지를 생각한다.
airports 데이터에서 UNIQUE한 국가만 리턴하기
두 가지 방법이 있다. DISTINCT 연산을 통해 고유값만 리턴해도 되고, COLLECT로 묶어서 그냥 리턴해줘도 된다.
둘의 차이는 여기잘 설명되어 있다.
1) 우리는 UNIQUE한 국가만을 리턴할 것이기 때문에, 그룹의 기준은 국가가 된다. 2)3) 뽑을 데이터는 따로 없고, 그룹 기준만 리턴한다.
// COLLECT만 사용하고, AGGREGATE이나 INTO는 사용하지 않는 예제
FOR airport IN airports
COLLECT
country = airport.country
RETURN country
// 동일한 연산
FOR airport IN airports
RETURN DISTINCT airport.countryairports 데이터에서 국가별로 공항 이름을 리턴하기
1) 국가별 공항 이름이기 때문에 기준은 ‘국가’가 된다. 2) 뽑을 데이터는 공항 이름의 목록이다 3) 목록이기 때문에 배열 형태로 묶어줘야 한다
배열 형태로 데이터를 묶어주는 연산은 뭐가 있었을까? 일단 AGGREGATE에는 그런 기능을 수행하는 연산자가 없다.
그렇다면 남은 연산자인 INTO를 써야겠구나!
FOR airport IN airports
COLLECT
country = airport.country
INTO names = airport.name
RETURN {
country,
names
}여기서는 공항의 이름만 사용하기 때문에 INTO에서 airport.name만을 모아왔다.
flights 데이터에서 공항별로 도착했던 비행편의 수와 비행편의 정보를 알고싶다
1) 도착 공항별 데이터이기 때문에 기준은 공항이 된다
2) 뽑을 데이터는 비행이 있었던 횟수와 비행편에 대한 정보이다
3) 횟수는 개수를 세는 COUNT 연산자를 쓰면 되고, 비행편은 모아주면 되겠구나!
FOR flight IN flights
LIMIT 10000 // 리밋!!
COLLECT
airport= flight._to
AGGREGATE
cnt = COUNT(1)
INTO flight_infos = flight.FlightNum
RETURN {
airport,
cnt,
flight_infos
}위 내용에 대한 심화로, 리턴된 결과에 더하여 공항별 풀네임과 국가, 도시를 알고 싶다면 어떻게 해야할까? 답은 아래에 적어두겠음
flights 데이터에서 공항별로 최초 출발 비행편의 시간과, 최종 출발 비행편의 시간을 알고싶다.
위 문제들을 해결했다면, 이것도 상당히 쉽기 때문에 설명은 생략한다!
FOR flight IN flights
LIMIT 10000 // 리밋!!
COLLECT
airport = flight._from
AGGREGATE
min_time = MIN(flight.DepTimeUTC),
max_time = MAX(flight.DepTimeUTC)
RETURN {
airport,
first_departure: min_time,
last_departure: max_time
}4. 그 외 연산들
COLLECT에서 사용할 수 있는 유용한 연산들이 더 있다.
COUNT
그룹별로 숫자를 셀 때, 위에서처럼 COUNT()를 사용해도 되지만 AQL에서 제공해주는 다른 방법도 있다.
COLLECT WITH COUNT INTO countVariableName
FOR flight IN flights
LIMIT 10000 // 리밋!!
COLLECT WITH COUNT INTO length
RETURN length혹은, 배열의 길이는 LENGTH()라는 연산자로도 쉽게 계산 가능하다. 아래 코드에서 LET의 사용에 주목하자. 많이 쓰게 될 예정이다.
LET records = (
FOR flight IN flights
LIMIT 10000 // 리밋!!
RETURN flight
)
RETURN LENGTH(records)MIN_BY, MAX_BY
SQL로 쿼리문을 열심히 짜다보면 시스템별로 문법이 약간씩 상이하다. 나는 주로 Presto 쿼리 엔진을 통해 작업하는데, Presto에는 MIN_BY, MAX_BY라는 유용한 함수가 있다.
얘가 어떤 역할을 하냐면, MAX_BY(a, b)로 쓰이며, “그룹별로 b값이 최대가 되는 레코드의 a값을 리턴해줘”의 역할을 해준다.
예를 들어, A라는 사람이 {‘음식’: ‘라면’, ‘시간’ : ‘아침}, {‘음식’: ‘돈가스’, ‘시간’ : ‘점심}, {‘음식’: ‘탕수육’, ‘시간’ : ‘저녁} 의 데이터를 가지고 있다고 가정해보자.
A가 가장 늦은 시간에 먹은 음식을 알려줘!라는 쿼리는 어떻게 구성해야할까? subquery를 통해 A의 가장 늦은 시간을 찾아내서, 해당 시간을 조회하는 방식도 있겠지만 MAX_BY를 쓰면 아주 간단해진다.
그냥 MAX_BY(음식, 시간)을 하게되면 시간이 최대인(가장 늦은 시간인) 데이터의 음식을 반환해주기 때문이다.
안타깝지만 AQL에도 해당 연산자는 없다. 하지만 아랑고DB 커뮤니티를 통해 아랑고DB 개발자들의 구현 방식을 배울 수 있었다. 그 값진 내용을 여기에 공유한다 :)
AQL에서 배열의 크기 비교는 element-wise하게 이루어진다. 즉, 0번째 인덱스의 값부터 비교를 해나가는 방식이다.
예를 들어, [1, 2, 3, 4]와 [-1]을 비교한다면, 0번째 인덱스의 값은 1이 크기 때문에 왼쪽의 배열이 더 크다.
[1, 2, 3, 4]와 [1, 2, 3, -1]을 비교한다면, 3번째 인덱스에 해당하는 4와 -1 중 4가 더 크기 때문에 왼쪽의 배열이 더 크다.
이 원리를 이용하면, MIN_BY와 MAX_BY를 구현 가능하다.
내가 알고싶은 값을 b, 기준이 되는 값을 a라고 하자. (위 예시에서는 음식이 b, 시간이 a가 되겠다)
각 레코드를 a_i, b_i로 표시한다면, 특정 그룹에 대해 N개의 데이터가 있었다면 아래처럼 될 것이다.
- [[a_0, b_0], [a_1, b_1], …, [a_N-1, b_N-1]]
위 배열에서 최대값을 구한다면, 어떤 의미를 가질까? 배열의 크기 비교는 원소끼리의 대응이라고 했으니까, 기준값 a끼리의 비교가 된다.
즉, MAX(배열) 연산을 하게 되면, 기준값 a가 가장 큰 배열이 리턴되며, 그 배열의 b값이 우리가 찾는 값이 된다.
마찬가지로 MIN(배열) 연산을 하게 되면, 기준값 a가 가장 작은 배열이 리턴되며, b값을 쓰면 된다.
이제 아래 문제를 풀어보자. 위에서는 시간만 리턴하는 문제였지만, 이제는 시간에 대응되는 값을 찾아야 한다.
flights 데이터에서 공항별로 최초 출발 비행편의 비행번호(FlightNum)와 최종 출발 비행편의 비행번호를 알고싶다.
답을 보기 전에, 꼭 끝까지 머리를 싸매고 문제를 해결해보자.
FOR flight IN flights
COLLECT
airport = flight._from
AGGREGATE
min_by_deptime_to = MIN([flight.DepTimeUTC, flight.FlightNum]),
max_by_deptime_to = MAX([flight.DepTimeUTC, flight.FlightNum])
RETURN
{
airport,
earlies: min_by_deptime_to[1],
latest: max_by_deptime_to[1]
}기준은 출발 시간이기 때문에 [출발 시간, 비행번호]의 배열에 대해 각각 MIN, MAX 연산을 취해주면 된다. 원리만 이해하면 정말 쉽다.
5. 심화 답
위에서 나온 심화 문제의 답은 아래에 있다.
핵심은, Document() 함수로 공항을 조회해 해당 결과를 리턴 값 안에 포함시켜주는 것이다.
여기서 COLLECT의 그룹 기준인 flight._to가 ArangoDB에서 _id에 해당하기 때문에, 이 값을 Document()에서 바로 호출해 접근이 가능한 원리이다.
FOR flight IN flights
LIMIT 10000 // 리밋!!
COLLECT
airport= flight._to
AGGREGATE
cnt = COUNT(1)
INTO flight_infos = flight.FlightNum
RETURN {
airport,
cnt,
flight_infos,
fullname: Document(airport).name,
country: Document(airport).country
}6. 어디까지 왔나
이번 시간까지 해서 아랑고DB를 사용하기 위한 기본적인 지식들은 모두 익혔다. 기초 AQL부터 그래프 횡단, COLLECT까지 모두 훑었기 때문에 이제 실전에서 잘 써먹기만 하면 된다.
이제 얼마 남지 않은 아랑고DB 관련 글들은 실제 데이터를 사용해 프로젝트를 진행하는 부분에 초점을 맞추려고 한다.
실제 프로젝트를 진행할 때, 기존 다른 형태로 저장되어 있던 데이터들은 어떻게 설계할 것이고, 손쉽게 아랑고DB에 넣을 것이며, 복잡한 데이터는 어떻게 뽑을 것인지를 다루려고 한다.
내가 현재 Python으로 구현해서 사용하고 있는 그래프 Mapper를 되도록 라이브러리화해서 사용할 예정이고, Kaggle에 있는 데이터를 하나 잡아서 프로젝트 용으로 쓸 것이다.
- 아랑고DB란? 왜 쓰는가?
- 아랑고DB 세팅하기 on Ubuntu
- 아랑고DB 쉘로 붙어서 명령어 체험해보기, 실체 파악해보기
- AQL(Arango Query Lang) 배워보기 1
- AQL(Arango Query Lang) 배워보기 2 - RETURN / UPDATE
- AQL(Arango Query Lang) 배워보기 3 - REPLACE / UPSERT / REMOVE
- 그래프 개념잡기
- 그래프 횡단하기 Graph Traversal
- (지금 보고있는 글) 데이터 모으기 COLLECT / AGGREGATE / MIN_BY, MAX_BY
- 프로젝트. 그래프를 통한 영화 추천시스템 만들어보기 1
- 프로젝트. 그래프를 통한 영화 추천시스템 만들어보기 2 (최종편)