<분석방법론> 코호트 분석 파헤치기
18 Apr 2022 | 데이터분석 코호트분석1. 코호트 분석이란? Cohort Analysis
코호트(동질 집단)란 무엇일까? 특정 기간동안 공통된 특성이나 경험을 공유하는 사용자 집단을 의미한다. 코로나 발생 초기에, 병원에서 코호트 격리를 한다는 기사가 많이 나왔는데 거기서 사용되는 의미와 동일하다.
코호트 분석(동질 집단 분석)은 이러한 유사 성질을 갖는 코호트를 만들어, 시간에 따른 각 코호트의 행동과 여러 지표들을 분석할 때 사용하는 기법이다.
여러 출처로부터 다양한 정의를 내리자면,
- 코호트 분석은 동종 집단이 나타내는 시간적 변모 양태를 분석하여 예측하고자 하는 연구이다.
- 코호트 분석은 사용자를 기간에 따라 그룹으로 분류하여 그룹의 행동과 유지율을 분석할 때 활용하는 기법이다.
- 코호트 분석은 시간 경과에 따라 유저 그룹을 추적하는 방법이다.
여기서 중요한 점은, 특정 기간 경험을 공유한다는 점과, 유사 속성을 갖는다라는 점이다.
코호트 테이블
이제 실제 코호트 분석에 쓰이는 테이블을 살펴보자. 출처는 GA에 있는 샘플 차트이고, 조건은 아래와 같다.
- 코호트 유형은 ‘획득 날짜’이다. 즉, 최초로 사이트에 접속한 날짜를 기준으로 코호트를 만들겠다는 의미이다.
- 코호트의 크기는 ‘일별’이다. 일 단위로 코호트를 분리하겠다는 의미이다.
- 측정 항목은 사용자 유지율이고, 7일간의 데이터를 살펴본다.
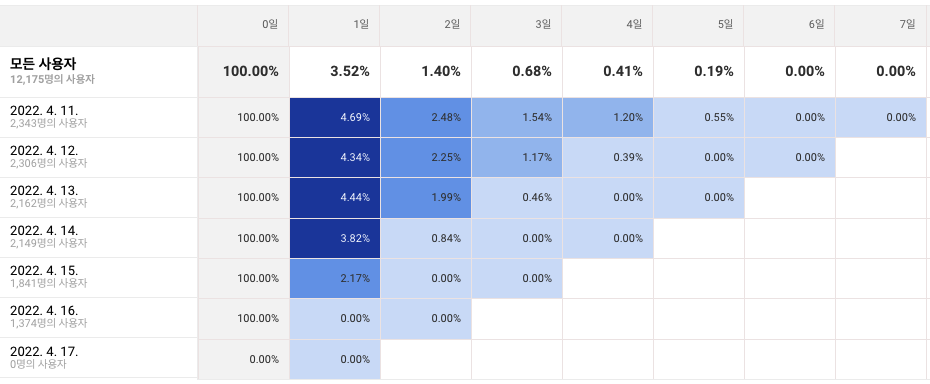
위 이미지에서 행(날짜 데이터)이 코호트이다. 간단히 해석해보자.
- 4월 10일, 1714명의 사용자가 최초로 접속했다. (사실 정말로 최초는 아닐테지만, 코호트의 시작점이라 그렇다).
- 4월 10일에 방문한 고객 중, 다음 날(+1일 열) 3.68%의 고객만이 재방문했다(유지되었다).
- 4월 10일에 방문한 고객 중, 6일 뒤(+6일 열), 0.88%의 고객만이 재방문했다.
- 4월 14일, 2149명의 사용자가 최초로 접속했다. (신규 유저)
- 4월 14일에 방문한 고객 중, 다음 날(+1일 열) 3.82%의 고객만이 재방문했다.
그럼 4월 14일에 방문한 총 고객은 몇 명일까? 2149명일까? 정답은 ‘그렇지 않다’이다. 코호트에 표기된 숫자는 새롭게 획득된 사용자 수를 의미한다. 즉, 4월 14일에 새롭게 유입된 고객이 2149명이라는 의미이다. 코호트 테이블만을 보고 4월 14일의 전체 방문자는 알 수 없다. 다만, 코호트 내의 값으로 어느정도 계산은 할 수 있다. 4월 14일의 방문자는 코호트 내의 아래 방문자들로 구성된다.
- 4월 14일의 신규 유입
- 4월 13일의 +1일 유저들 (재방문)
- 4월 12일의 +2일 유저들 (재방문)
- 4월 11일의 +3일 유저들 (재방문)
- 4월 10일의 +4일 유저들 (재방문)
- 그리고 코호트 기간을 벗어나는, 이전 방문자들 중 재방문자들
코호트 테이블의 구현
여기서 짚고 넘어가야 할 부분이 있다. 코호트 분석에서 집계 방식은 크게 두 가지가 있다.
- 코호트의 유입 날짜를 기준으로 하는 것
- 코호트의 유입 날짜와 직전 기간을 기준으로 하는 것 (Rolling retention)
예를 들어, 사용자 A가 4월 10일의 코호트에 속하는데, 4월 11일과 4월 13일에 방문했다고 해보자. 1번 방식으로는 4월 11일, 4월 13일이 모두 집계되지만 2번 방식에서는 4월 11일이 마지막 집계가 된다. 왜냐하면 4월 12일에는 방문을 하지 않았기 때문에, 직전 기간이 12일이 되는 13일도 집계가 되지 않는 것임.
이에 대한 자세한 내용을 찾아보려 했는데, 구체적으로 다룬 내용을 찾지 못했다. 나중에 찾게 되면 추가하겠음. GA는 1번 방식을 택하고 있다.
2. 코호트 분석의 의미
코호트 분석이 왜 중요한걸까? 개인적으로는 행동 분석(Behavioral Analytics)을 기반으로 하는 분석 기법들이 대부분 동일한 목적을 갖는다고 생각하는데, 데이터를 전체로 보는 것이 아닌 부분으로 나누어 보아야 행동 분석의 의미가 있기 때문이다.
- 이벤트를 기반으로 데이터를 나누게 되면, 퍼널 분석이나 AARRR과 같이 고객의 각 행동(이벤트)을 단계별로 나누어 각 단계를 면밀히 관찰할 수 있다.
- 사용자를 기반으로 데이터를 나누게 되면, 일반적인 세그먼트나 세그먼트의 일종인 코호트 분석, RFM 분석처럼 유사한 고객별로 면밀히 관찰할 수 있다.
이벤트를 중심으로 살펴보든, 사용자를 중심으로 살펴보든 유사한 특성을 지닌 단계(그룹)별로 나누어 보는 게 데이터 분석이 훨씬 용이하기 때문이다. 더 나아가, 사용자를 기반으로 타겟을 쪼개고 그 타겟별로 이벤트 기반 분석을 할 수 있다. 즉, 세그먼트별로 퍼널이 어떻게 다른지도 비교해 볼 수 있고 더 세분화된 분석이 가능하다. 이러한 세분화된 분석은 맞춤 마케팅을 가능하게 해준다.
좀 더 직접적인 의미를 찾자면, 코호트 분석은 고객의 유지율(그리고 이탈률)을 분석하는 데 탁월한 지표이다. 사용자가 감소하는 시기를 포착하여 개선방안을 제시할 수 있기 때문이다. 예를 들어, 사용자가 급격히 이탈하는 지점이 발생하면 그 시기에 대한 조사를 통해 문제가 있는 부분을 개선할 수 있고, 푸시 알림 등을 통해 이탈한 고객을 다시 유입시킬 수도 있다.
3. 코호트 분석 해보기
이제 실제 데이터셋을 통해 코호트 테이블을 그려보고, 간단한 분석을 진행해보자.
1) 데이터 소개
캐글에서 데이터를 가져왔고, 여기서 다운로드 받을 수 있다. ‘2019-Oct’ 부터 ‘2020-Feb’ 까지 5개 파일 모두 다운받으면 된다.
이 과정이 귀찮은 사람을 위해 이미 정제한 데이터도 올려두겠다. 여기를 눌러서 다운로드하기
데이터는 화장품을 다루는 이커머스가 출처이며, ‘상품 클릭 view’, ‘장바구니 담기 cart’, ‘장바구니 제외 remove_from_cart’, ‘구매 purchase’ 네 가지 이벤트에 대한 정보를 담고 있다. 아쉬운 점은 단순히 상품 클릭이 아닌, 사이트에 최초 접속한 레코드가 없다는 점인데 그냥 감안하고 진행하도록 하겠다.
2) 데이터 정제
여기에는 2019년 10월부터 2020년 2월까지 총 5개월의 데이터가 담겨있다. 하지만 개별 데이터가 너무 크기 때문에, 각 월별로 고유한 1000명의 데이터만 뽑아서 샘플링한 데이터를 쓴다.
더 구체적으로, 고유한 1000명에 더해 이전 기간의 코호트를 유지하기 위해 앞선 기간의 유저는 그대로 유지하는 방식을 택한다. 즉,
- 파일별 1000명을 샘플링하여, 해당 1000명의 데이터를 모두 가져온다.
- 이전 기간의 사용자를 기록해서, 이후 파일에서도 동일한 사용자가 나오면 포함한다.
import pandas as pd
import random
whole_target_pool = set()
for file in ['2019-Dec', '2019-Nov', '2019-Oct', '2020-Feb', '2020-Jan']:
target = pd.read_csv('{}.csv'.format(file))
sample_targets = random.sample(list(target.user_id.unique()), 1000)
whole_target_pool.update(sample_targets)
# 1000명의 샘플에 있거나, 이미 뽑은 앞선 목록에 있으면 타겟으로 넣는다.
new_target = target[target.user_id.isin(sample_targets) | target.user_id.isin(whole_target_pool)]
print(len(new_target.user_id.unique()), new_target.shape)
new_target.to_csv('{}-1000.csv'.format(file), index=False)
1000 (9418, 9)
1141 (16677, 9)
1241 (17031, 9)
1270 (21948, 9)
1482 (27129, 9)
이제 5개의 파일을 하나로 합쳐서, 최종 파일을 만든다. 앞서 말한대로 이미 정제된 파일은 위에 링크를 달아두었다.
whole_df = pd.DataFrame()
for file in ['2019-Dec', '2019-Nov', '2019-Oct', '2020-Feb', '2020-Jan']:
target = pd.read_csv('{}-1000.csv'.format(file))
whole_df = pd.concat([whole_df, target])
print(whole_df.shape)
whole_df.head(3)
(92203, 9)
| event_time | event_type | product_id | category_id | category_code | brand | price | user_id | user_session | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019-12-01 04:09:27 UTC | view | 5724233 | 1487580005092295511 | NaN | NaN | 14.60 | 504201396 | 10c40773-05d3-4fd8-af4c-16e8c9999bf4 |
| 1 | 2019-12-01 05:18:49 UTC | view | 5900639 | 1487580005713052531 | NaN | ingarden | 4.44 | 502359395 | 8dad7a10-5dc3-4c94-9880-bedbf53eeb1a |
| 2 | 2019-12-01 05:46:02 UTC | view | 5651938 | 1487580012902088873 | NaN | NaN | 6.33 | 574133915 | 4c7bf0a0-5f68-414c-b126-93b372b26a65 |
whole_df.to_csv("ecommerce_cosmetics_sampled.csv", index=False)
3) SQLite에 데이터 쌓기
다른 방식으로 진행해도 되지만, 일반적으로 데이터가 DB에 들어있다고 가정하고 SQL을 통해 코호트 테이블의 기초 데이터를 만들고자 한다.
여기서는 데이터베이스로 SQLite을 사용한다. SQLite은 이름 그대로 정말 라이트하게 사용할 수 있는 SQL DB 엔진이다. 별도의 설정도 필요 없고, 그냥 설치하고 곧바로 파이썬 소스로 데이터를 넣어주면 된다. 나는 맥OS를 쓰는데, 이미 설치가 되어 있어 생략했다. 여기서 최신 버전을 다운받자.
관계형 DB에서 가장 먼저 할 일은, DB 서버에 연결하고, 개별 DB에 접속하는 일이다. SQLite은 별도로 서버 개념이 없기 때문에, 실제로 코드를 돌리는 곳에 데이터를 저장한다.
아래서 쓰인 SQLite 관련 도큐멘테이션은 여기를 참고하자. 별도로 다루지는 않는다.
import sqlite3
# 일반적으로 connect는 host에 연결하는 행위이지만, SQLite은 곧바로 DB에 연결한다.
con = sqlite3.connect('ecommerce.db')
# 명령어를 실행해주기 위한 커서 선언
cur = con.cursor()
# event 테이블을 만들어준다. 일단 모두 text 타입으로 선언한다.
cur.execute("""
CREATE TABLE events
(event_time text, event_type text, product_id text, category_id text, category_code text, brand text, price text, user_id text, user_session text)
""")
import pandas as pd
# 아까 만든 데이터를 불러온다.
data = pd.read_csv('ecommerce_cosmetics_sampled_10000.csv')
lists = []
# 튜플 형태로 리스트에 넣어준다
for idx, row in data.iterrows():
lists.append(tuple([*row.values]))
# executemany를 통해 한 번에 데이터를 넣는다
cur.executemany("""INSERT INTO events VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)""",lists)
# 트랜잭션을 수행하는 모든 함수는 반드시 커밋을 해줘야 실제 트랜잭션이 수행된다
con.commit()
# 연결을 닫는다
con.close()
이제 데이터가 생성되었는지 확인해 볼 차례다. 위에서 SQLite을 설치했다면, 터미널을 열고 해당 소스를 실행시킨 위치로 이동하자. 즉, ecommerce.db 파일이 생성된 위치로 가면 된다.
해당 위치에서 아래 명령어를 실행한다.
sqlite3 ecommerce.db #이제 sqlite3 DB에 접속했다
# sqlite에서는 시스템 명령어를 쓸 때 '.'을 앞에 붙인다
sqlite> .tables #전체 테이블 목록을 읽어온다
events #아까 생성한 events 테이블이 있어야 정상이다
sqlite> .headers on #출력 시 헤더를 보여주도록 설정을 바꾼다
sqlite> SELECT COUNT(*) FROM events; #테이블의 전체 행 개수를 불러온다
95806 #랜덤 샘플링이기 때문에 값은 약간씩 다르다
sqlite> SELECT * FROM events LIMIT 1;
# 결과가 출력된다
sqlite> .exit #혹은 .quit으로 쉘을 종료한다
데이터가 쌓인 것을 확인했다. 이번 글의 중점은 코호트 분석이므로 데이터를 탐색하고, 들여다보고, 빈 값을 채우는 등의 프로세스는 생략한다.
4) SQL로 데이터 기반 만들기
이제 실제 데이터를 만들어보자. 그 전에, 어떤 코호트 분석을 할 것인지 정하고 가자.
- 코호트의 유형은? 최초 상품 클릭(view) 기준 코호트
- 코호트의 크기는? 1주 단위
- 코호트의 측정 항목은? 유지율
- 코호트의 전체 기간은? 9주
- 코호트 집계 방식은? 일반적인 방식. 기준 롤링을 하지 않는다. 즉, 코호트 기준일에만 부합하면 집계한다.
데이터는 어떻게 만들까? 코호트 테이블을 행렬로 볼 때, 각 원소는 (기준 코호트, 기준 코호트로부터의 경과일)의 쌍이라고 할 수 있다.
즉, (코호트1, 코호트1 +1주), (코호트1, 코호트1 +2주)… 를 기준으로 그룹을 만든 것이 코호트 테이블이 된다.
con = sqlite3.connect('ecommerce.db')
cur = con.cursor()
result = con.execute("""
WITH
base AS (
-- 문자열을 날짜로 바꿔주기 위한 용도
SELECT
user_id,
-- '주간'만 빼내는데, 연도가 바뀌면 계산이 틀어지기 때문에 현재 연도에서 가장 낮은 연도인 2019년을 뺀 만큼에 52를 곱한 값을 더해준다
-- 즉, 2019년 마지막 주는 52가 되고, 2020년의 첫 주는 1 + (2020-2019)*52 = 53이 된다
STRFTIME('%W', DATE(SUBSTR(event_time, 1, 10))) + (STRFTIME('%Y', DATE(SUBSTR(event_time, 1, 10))) - 2019) * 52 AS event_week
FROM events
WHERE event_type = 'view'
-- 9개의 주간으로 나누기 위해 기간을 제한해준다
AND STRFTIME('%W', DATE(SUBSTR(event_time, 1, 10))) + (STRFTIME('%Y', DATE(SUBSTR(event_time, 1, 10))) - 2019) * 52 <= 47
)
,first_view AS (
-- 우선 사용자별로 최초 유입 월을 찾는다. 이게 코호트가 된다.
SELECT
user_id,
MIN(event_week) AS cohort
FROM base
GROUP BY user_id
)
,joinned AS (
-- 기존 데이터에 위에서 찾은 코호트를 조인해준다. 그리고 기존 이벤트 월과 코호트 월의 차이를 빼준다
SELECT
t1.user_id,
t2.cohort,
t1.event_week,
t1.event_week - t2.cohort AS week_diff
FROM base t1
LEFT JOIN first_view t2
ON t1.user_id = t2.user_id
)
-- (기준 코호트, 기준 코호트로부터의 경과주) 쌍을 만들어 고유한 사용자 수를 센다
SELECT
cohort,
week_diff,
COUNT(DISTINCT user_id)
FROM joinned
GROUP BY cohort, week_diff
ORDER BY cohort ASC, week_diff ASC
""").fetchall()
이제 데이터 추출이 끝났다. 판다스로 가져와서 행렬로 만들고, 추가적인 시각화까지 진행해보자.
5) 코호트 테이블 만들기
# 데이터프레임으로 만들고
# 컬럼의 이름을 바꿔주고
# 피벗 기능을 이용해 코호트 테이블 형태로 만들어준다
# 빈 값은 0으로 채운다
pivot_table = pd.DataFrame(result)\
.rename(columns={0: 'cohort', 1: 'duration', 2: 'value'})\
.pivot(index='cohort', columns='duration', values='value')\
.fillna(0)
pivot_table
| duration | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| cohort | |||||||||
| 39 | 3402.0 | 576.0 | 456.0 | 398.0 | 355.0 | 248.0 | 226.0 | 261.0 | 253.0 |
| 40 | 2790.0 | 405.0 | 296.0 | 230.0 | 204.0 | 185.0 | 189.0 | 186.0 | 0.0 |
| 41 | 2324.0 | 315.0 | 198.0 | 141.0 | 116.0 | 140.0 | 143.0 | 0.0 | 0.0 |
| 42 | 2185.0 | 244.0 | 147.0 | 137.0 | 137.0 | 136.0 | 0.0 | 0.0 | 0.0 |
| 43 | 2113.0 | 196.0 | 114.0 | 132.0 | 107.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 44 | 2101.0 | 180.0 | 193.0 | 145.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 45 | 1988.0 | 233.0 | 148.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 46 | 2229.0 | 277.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 47 | 2323.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
위 상태는 유지되는 고유 유저수를 보여주고 있기 때문에 비율로 바꾸어 주겠다. 또한 판다스에서 제공하는 background_gradient를 이용해 히트맵을 그려준다.
# 첫 번째 기간으로 나누어 비율로 만들어주고
# %가 나오도록 포맷팅을 해주고
# 색을 입혀준다
round(pivot_table.div(pivot_table[0], axis='index'), 2)\
.style.format({k: '{:,.0%}'.format for k in pivot_table})\
.background_gradient(cmap ='Blues', axis=None, vmax=0.2)
| duration | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| cohort | |||||||||
| 39 | 100% | 17% | 13% | 12% | 10% | 7% | 7% | 8% | 7% |
| 40 | 100% | 15% | 11% | 8% | 7% | 7% | 7% | 7% | 0% |
| 41 | 100% | 14% | 9% | 6% | 5% | 6% | 6% | 0% | 0% |
| 42 | 100% | 11% | 7% | 6% | 6% | 6% | 0% | 0% | 0% |
| 43 | 100% | 9% | 5% | 6% | 5% | 0% | 0% | 0% | 0% |
| 44 | 100% | 9% | 9% | 7% | 0% | 0% | 0% | 0% | 0% |
| 45 | 100% | 12% | 7% | 0% | 0% | 0% | 0% | 0% | 0% |
| 46 | 100% | 12% | 0% | 0% | 0% | 0% | 0% | 0% | 0% |
| 47 | 100% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% |
6) 해석하기. 가져갈 수 있는 의미
이제 코호트 테이블을 읽어보자. 왼쪽의 39는 2019년의 39번째 주를 의미한다. 그리고 오른쪽의 duration에서 1~8은 코호트 주로부터 그만큼 경과한 주를 의미한다.
- 모든 코호트에서 1기간이 경과했을 때의 유지율은 평균 10%가 조금 넘는다.
- 코호트39에서 8기간이 경과했을 때의 유지율은 9%이다. 즉 39번째 주에 방문하여 상품을 본 고객 중, 8주 이후에도 똑같이 행동한 고객은 그 중 9%라는 의미이다. (단, 이 고객이 1~7주차 사이에도 그랬는지는 알 수 없다.)
- 3기간이 경과했을 때의 유지율은 4~8% 정도로 매우 낮은 편이다.
전반적으로, 유지율이 매우 낮은 것을 알 수 있다. 물론 상품을 본(view) 이벤트를 기준으로 하기 때문에 사이트 방문이라고는 볼 수 없지만, 일반적으로 이커머스에서 유지율(재방문율)은 낮아도 20% 정도인 업체가 많다. 이런 경우 대부분 유입 트래픽 광고를 엄청나게 뿌려대지만 당장 그 때만 고객이 유입하고 이후에 리타겟팅이 안 되는 경우가 많다.
또 어떤 데이터를 읽을 수 있을까? 테이블만 봐서는 사실 잘 와닿지 않는다. 우리는 이 분석을 통해 얻어가고자 하는 바를 미리 정의하지 않았기 때문이다. 미리 정의하지 않았기 때문에 코호트 분석을 통해 찾아내고자 하는 내용이 없었고, 그에 맞는 평가 지표도 선정되지 않았다.
7) 또다른 코호트 접근
이번에는 10월 한 달 동안 사용자가 본 브랜드별로 코호트를 만든다고 가정해보자. 마케터인 나는 브랜드별로 사용자의 성향이 다르고, 방문 성향도 다를 것이라고 생각한다. 따라서 브랜드에 따라 코호트를 나누었다.
result_2 = con.execute("""
WITH
base AS (
-- 문자열을 날짜로 바꿔주기 위한 용도
SELECT
user_id,
STRFTIME('%W', DATE(SUBSTR(event_time, 1, 10))) + (STRFTIME('%Y', DATE(SUBSTR(event_time, 1, 10))) - 2019) * 52 AS event_week,
event_type,
brand
FROM events
-- 9개의 주간으로 나누기 위해 기간을 제한해준다
WHERE STRFTIME('%W', DATE(SUBSTR(event_time, 1, 10))) + (STRFTIME('%Y', DATE(SUBSTR(event_time, 1, 10))) - 2019) * 52 <= 47
AND brand IS NOT NULL
AND event_type = 'view'
AND DATE(SUBSTR(event_time, 1, 10)) >= '2019-10-01'
AND DATE(SUBSTR(event_time, 1, 10)) <= '2019-10-31'
)
,first_view AS (
SELECT
user_id,
brand AS cohort,
MIN(event_week) AS cohort_time
FROM base
GROUP BY user_id, brand
)
,joinned AS (
SELECT
t1.user_id,
t2.cohort,
t1.event_week,
t1.event_week - t2.cohort_time AS week_diff
FROM base t1
LEFT JOIN first_view t2
ON t1.user_id = t2.user_id
AND t1.brand = t2.cohort
)
SELECT
cohort,
week_diff,
COUNT(DISTINCT user_id)
FROM joinned
GROUP BY cohort, week_diff
ORDER BY cohort ASC, week_diff ASC
""").fetchall()
# 데이터프레임으로 만들고
# 컬럼의 이름을 바꿔주고
# 피벗 기능을 이용해 코호트 테이블 형태로 만들어준다
# 빈 값은 0으로 채운다
pivot_table_2 = pd.DataFrame(result_2)\
.rename(columns={0: 'cohort', 1: 'duration', 2: 'value'})\
.pivot(index='cohort', columns='duration', values='value')\
.fillna(0)\
.sort_values(by=[0], ascending=False)\
.iloc[:10, :]
# 상위 10개만 잘랐다
pivot_table_2
| duration | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| cohort | |||||
| runail | 1641.0 | 182.0 | 104.0 | 67.0 | 15.0 |
| irisk | 1354.0 | 126.0 | 77.0 | 52.0 | 25.0 |
| masura | 840.0 | 99.0 | 52.0 | 26.0 | 11.0 |
| grattol | 730.0 | 106.0 | 50.0 | 29.0 | 11.0 |
| estel | 649.0 | 28.0 | 13.0 | 8.0 | 3.0 |
| jessnail | 595.0 | 38.0 | 13.0 | 6.0 | 3.0 |
| ingarden | 560.0 | 61.0 | 28.0 | 15.0 | 4.0 |
| kapous | 512.0 | 24.0 | 14.0 | 5.0 | 1.0 |
| bpw.style | 467.0 | 46.0 | 30.0 | 13.0 | 4.0 |
| uno | 466.0 | 34.0 | 19.0 | 9.0 | 5.0 |
# 첫 번째 기간으로 나누어 비율로 만들어주고
# %가 나오도록 포맷팅을 해주고
# 색을 입혀준다
round(pivot_table_2.div(pivot_table_2[0], axis='index'), 2)\
.style.format({k: '{:,.0%}'.format for k in pivot_table_2})\
.background_gradient(cmap ='Blues', axis=None, vmax=0.2)
| duration | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| cohort | |||||
| runail | 100% | 11% | 6% | 4% | 1% |
| irisk | 100% | 9% | 6% | 4% | 2% |
| masura | 100% | 12% | 6% | 3% | 1% |
| grattol | 100% | 15% | 7% | 4% | 2% |
| estel | 100% | 4% | 2% | 1% | 0% |
| jessnail | 100% | 6% | 2% | 1% | 1% |
| ingarden | 100% | 11% | 5% | 3% | 1% |
| kapous | 100% | 5% | 3% | 1% | 0% |
| bpw.style | 100% | 10% | 6% | 3% | 1% |
| uno | 100% | 7% | 4% | 2% | 1% |
이번에는 어떨까? 브랜드 코호트마다 확실히 유지율이 다른 것을 알 수 있다. 특정 브랜드를 찾았던 고객은 계속해서 방문을 하고, 다른 브랜드들은 그렇지 않다. 여기에는 브랜드의 속성이 주는 재구매주기라든지 여러 요소들이 작용할 것이다. 브랜드를 떠나 화장품의 카테고리별로 보는 것도 좋은 분석이 될 수 있다.
4. 마치며
코호트 분석에 대해 정리해두었더 내용들을 글로 옮길 수 있어 마음이 편안하다. 😃 아무쪼록 누구에게든 도움이 되었으면 좋겠고, 앞으로도 데이터 분석과 관련한 글들을 계속해서 작성할 예정이다!
생각중인 주제로는 퍼널 분석, RFM 세그멘테이션, LTV, 전환기여(FirstTouch, LastTouch) 등이 있는데, 다양하게 다루어보도록 하겠다 :)