

<인과추론> 2. 편향과 인과추론의 식별, 추정
29 May 2025 | 인과추론 데이터분석1. 편향이란?
편향(bias)은 인과관계와 연관관계를 다르게 만드는 요소이다. 편향을 이론적으로 이해하기 위해 수식으로 표현해보자. 이를 위해 관측 데이터에서의 연관 관계를 먼저 수식으로 표현해보고, 실제 이론상의 인과 관계와 어떤 부분이 다른지 비교하는 방식을 택한다.
관측 데이터에서의 연관 관계
이전 글에서 보았던 크리스마스 할인이 회사의 판매량 차이에 미친 영향을 파악하기 위한 사례를 들어보자.
- 우리가 잘못된 방식으로 집계하려고 했던 인과 관계는 다음과 같다. 이때 실험군의 관측된 결과는 $Y_1$ 이고, 대조군의 결과는 $Y_0 이다.$
-
여기서 실험군의 반사실적 결과를 더하고 뺀다
\[E[Y_1|T=1] - E[Y_0|T=1] + E[Y_0|T=1] - E[Y_0|T=0]\] -
식의 순서를 바꾸고 기대값을 합치면 다음과 같다
\[\underbrace{E[Y_1-Y_0|T=1]}_{\text{ATT}} + \underbrace{\{E[Y_0|T=1] - E[Y_0|T=0]\}}_{\text{편향}}\]
위 편향식이 시사하는 바를 잘 기억하자.
- 연관관계는 ATT에 편향을 더한 값과 같다.
- 편향은 처치와 관계없이 실험군과 대조군이 어떻게 다른지에 따라 다르다.
- 즉, 수많은 요소가 처치와 함께 변화하므로 이러한 편향을 만들어내고, 앞선 크리스마스 할인 예시에서는 회사의 규모, 위치, 경영 방식, 할인 시기 등 여러 요소들이 데이터에 편향을 만들어내고 있을 것이다.
2. 인과효과 식별과 추정
인과추론의 근본적인 문제는 동일한 실험 대상이 ‘처치’를 받은 상태와 받지 않은 상태를 동시에 관측할 수 없다는 점이다. 그리고 이러한 제약 속에서 우리에게 주어진 관측 데이터를 통해 실제 인과 효과를 추정하는 것이 인과 추론의 목적이라고 할 수 있다.
위 목적을 이루기 위한 인과추론의 과정은 크게 두 가지로 분류된다.
- Identification (식별): 관측 가능한 데이터로 인과 추정량을 표현하는 방법을 알아내는 단계
- 특정한 가정이 충족될 경우, 인과효과를 통계적으로 추론할 수 있는가?
- Estimation (추정): 데이터를 활용해서 식별한 인과 추정량을 추정하는 단계
- 주어진 데이터에서 우리가 원하는 인과효과를 실제로 계산할 수 있는가?
특히 식별 단계는 편향을 없애는 과정으로도 볼 수 있는데, 만약 편향이 없어진다면 연관 관계는 인과 관계가 된다. 즉, $E[Y_0|T=0] = E[Y_0|T=1]$의 의미는 어렵게 생각할 것 없이 대조군과 실험군이 비교 가능함을 의미한다. (= exchangeability, ceteris paribus, all other things being equal)
결국 앞으로 배울 인과추론에서 가장 중요한 것은,
- 어떻게 1) 인과 효과를 식별하고 2)효과를 추정할 것인가를 결정하는 일이다.
- 특히 앞으로 배우게 될 여러 내용들은 인과 효과를 어떻게 식별할 것인가?에 중점을 둔다.
- 인과효과를 식별한다는 것은 편향을 제거하여 대조군과 실험군이 교체 가능한(=exchangeable) ceteris paribus 상태로 만든다는 것이고,
- 그렇기 때문에 흔히들 A/B Test라고 부르는 RCT(Randomized Controlled Trial)가 실제 인과 효과를 추정하기 위한 “Golden Standard”로 불리는 것이다. 왜? 별다른 어려운 설계 없이도 대조군과 실험군이 균등하게 분배된 ceteris paribus 상태를 만들 수 있기 때문이다.
- 그럼 이러한 RCT가 불가능한 상황에서는 어떻게 할까?
3. 인과추론의 위계 맛보기
인과추론의 위계는 다음과 같다.
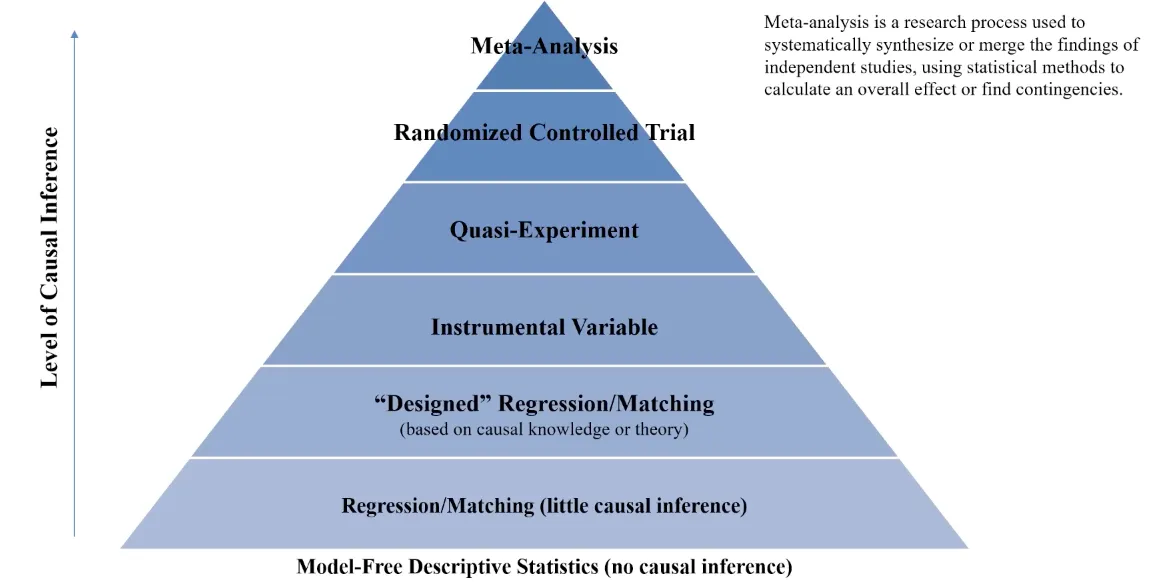
- Meta Analysis를 제외하면 RCT는 인과추론의 최상위 위계로 존재하고, 실제 실무적으로도 가장 많이 쓰이는 기법이다.
- 모종의 이유로 RCT를 실시하지 못했다면, 그 다음은 머리를 쥐어 짜내어 도메인에서 활용할 수 있는 모든 조건들을 고려해 어떤 방법론으로 인과효과를 ‘식별’할 것인지 정해야 한다.
- 여기에는 DiD (Difference-in-DIfferences), RDD (Regression Discontinuity), SCM (Synthetic Control Method)와 같은 방법론들이 있고, 도구변수 IV 를 활용하여 효과를 식별하는 방법들, PSM을 활용해 두 그룹을 유사하게 만들어주는 매칭 기법, ML 기반의 추론 기법 등 다양한 방법론들이 존재한다.
- 위 복잡한 방법론들이 싫으면 다 RCT로 진행하면 되는 거 아닌가 싶지만 조직의 데이터 고도화 수준에 따라 실험이 아예 불가능하거나 일부 실험만 진행해야 하는 경우도 있고, 실험 환경이 잘 갖춰져있더라도 정책/윤리적인 부분에 관한 A/B 스플릿은 어려운 경우가 많기 때문에 결국 어떤 상황에서 어떤 방법을 내가 활용할 수 있을지를 잘 알아둘 필요가 있다.
이 모든 방법론들에서 공통으로 마음 속에 새겨두면 좋을 것이 있다. 결국에 중요한 것은 내가 변수로 사용하는 데이터들의 관계를 잘 이해하는 것이다. 어떤 요소가 편향을 발생시키는지, 그리고 각 변수들이 어떤 관계를 맺고 있는지를 인과 그래프 등을 통해 표현하는 연습을 해두는 것이 좋다. (기회가 되면 글로 다루겠다) 왜냐하면 결국 인과 그래프가 잘 정리된 데이터라면, 단순한 회귀 모형을 사용해서 편향 요인들을 통제한 뒤 인과효과를 추론해도 되기 때문이다.
벌써부터 너무 많은 것을 알아야 한다는 생각은 하지 말고, 천천히 하나하나 배워서 정리해가자.
4. 참고 자료
- 실무로 통하는 인과추론 with Python 서적
- Causal Inference for the Brave and True
- 인과추론의 데이터 과학